Context graphs: great on paper, risky in practice
In late December Foundation Capital made the claim that Context graphs are "AI's trillion-dollar opportunity." I'm not here to disagree, but I do think these systems carry significant risk: how can we be certain that we have agents capturing the full set of essential decision traces? How can we ensure the decision traces reflect the true rationale behind decisions? Is all of this previously-ephemeral context actually something we want to persist?
Defining a couple of things
Decision trace: a structured record of how a system arrived at a particular choice in a specific context. It might capture things like assumptions, constraints, the available alternatives, and the factors that made one outcome preferable at that moment in time.
Context graph: the set of decision traces connected. Nodes might represent possible facts, options, outcomes. Edges contain reasoning relations. The decision traces contained are pathways of edges that justified a single choice.
Toy context graph example
For the sake of argument, let's compose a contrived example (although in this case I believe the ability to demonstrate the risk in a contrived example highlights the risk in a real-world example).
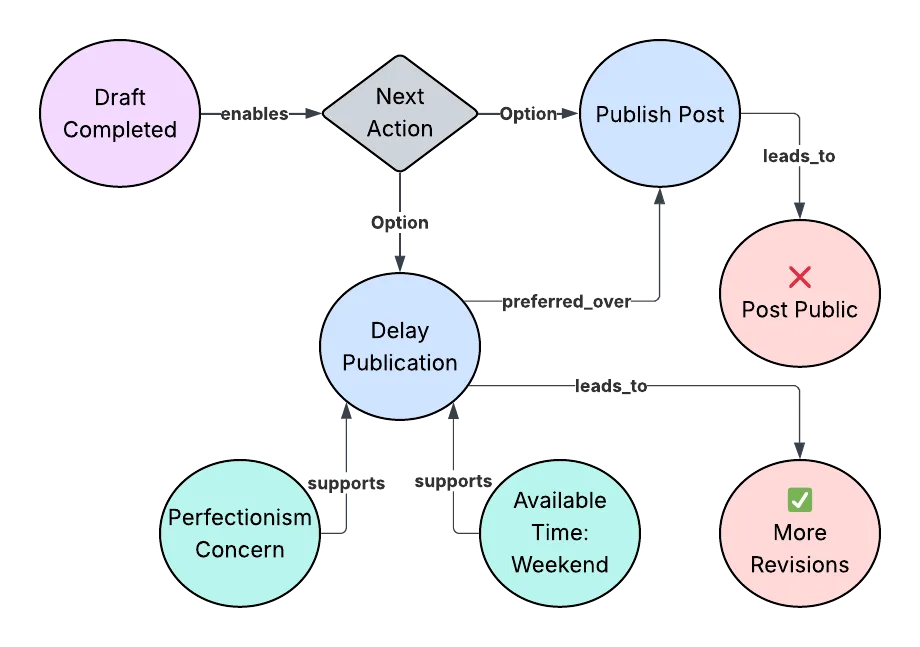
In this example, I've completed a draft blog post, triggering a state transition, unlocking a decision point. The available contextual signals, perfectionism concerns and available time to work, were evaluated alongside the two options.
Those signals favored delaying publication and it is at this point that the decision trace has been effectively persisted. Ephemeral context has been compressed into durable structure. That compression is where things get interesting, but also risky.
What could go wrong?
Incomplete graph (missing subtle but crucial context)
Our blog system fails to record audience expectations on publication cadence, history of abandoned drafts, or author burnout risk. Every delay seems reasonable with the data and decision traces we have.
You might have a counterargument for each of these, but the real point is there's no surefire way to know if all the crucial context is being captured. This is also a problem in pre-agentic systems (streetlight effect?), of course, but in the systems described by Foundation Capital, the problems will cascade and compound very rapidly.
Confounding issues (a byproduct of incompleteness)
Certain decision trace paths are reinforced over time, and some causal links between inputs and outcomes emerge. The problem is the actual cause is represented in some context not recognized by any agent in the system.
An environment change invalidates all stored decision rationale
Perhaps I've always been blogging at low cost, mostly for myself, and cadence doesn't really matter because nobody reads what I write anyways (this sounds familiar, actually 🤔). Let's set aside the fact that this begs the question: why do you have an agentic context-graph-based system helping you publish your blog posts, then?
Now what happens when these conditions change? You now have a devoted following of readers. It's January and you've resolved to write more. Your blogging infrastructure provider now charges prohibitively expensive fees for publishing your content.
This is an example of context drift, again not unique to these proposed systems, but perhaps more expensive and difficult to update for (I haven't thought deeply about what a context graph data migration might look like, but my intuition says that it's probably scary).
Goodhart's law
Let's say one particular agent is a bit more zealous in its decision trace contributions than other agents. How does this affect in-context learning? Maybe that particular agent's context often results in favorable outcomes, and so the zealous agent becomes even more zealous, reinforcing the behavior. Suddenly, as Charles Goodhart may have said, upon logging your context it has ceased to be good context. Or something like that.
Conclusion
The incomplete set of risks I've described here are risks in any system, agentic or not, context graph of decision traces or not. But the point is while the concept is beautiful, you have to be even more careful, because the sheer volume of information these systems will strive to leverage is orders of magnitude more than what legacy systems are working with.
They propose pulling previously ephemeral context like Slack messages, informal reasoning, and half-formed justifications into durable and queryable structures. My argument is that this is both powerful and dangerous.
Which context was never meant to last? In some systems today, forgetting is not a failure mode, but a safety mechanism.